fordRediSearch
 RediSearch
RediSearch

Data Lifecycle
Create a Schema
Add documents
Search/Aggregate
Query Language
Goals
Simple
Powerful
Simple Word Matching
Prefix Matching
Negation
Optional Term
Fuzzy Matching
Numeric Filter
Geo Filter
Tag Filter
Full-Text Search
Stop Words
Stemming
Slop
With or without content
Matched text highlight
Synonyms
Spell Check
Phonetic Search
Weights & Scores
Scoring Functions
Aggregations
Aggregation Pipeline

Grouping
Functions — Strings
Functions — Numbers
Functions — Time
Aggregate Command
Auto-complete
Radix Tree-based
Optimized for real-time, as-you-type completions

Simple API
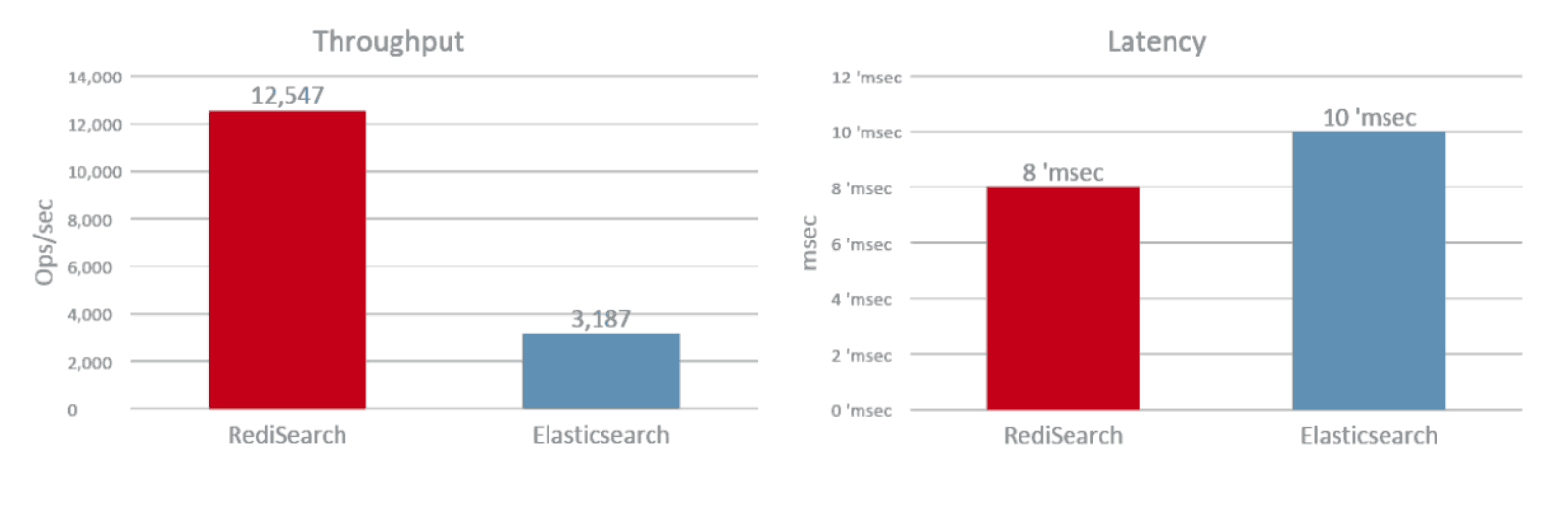
RediSearch vs Elasticsearch
Indexing Performance
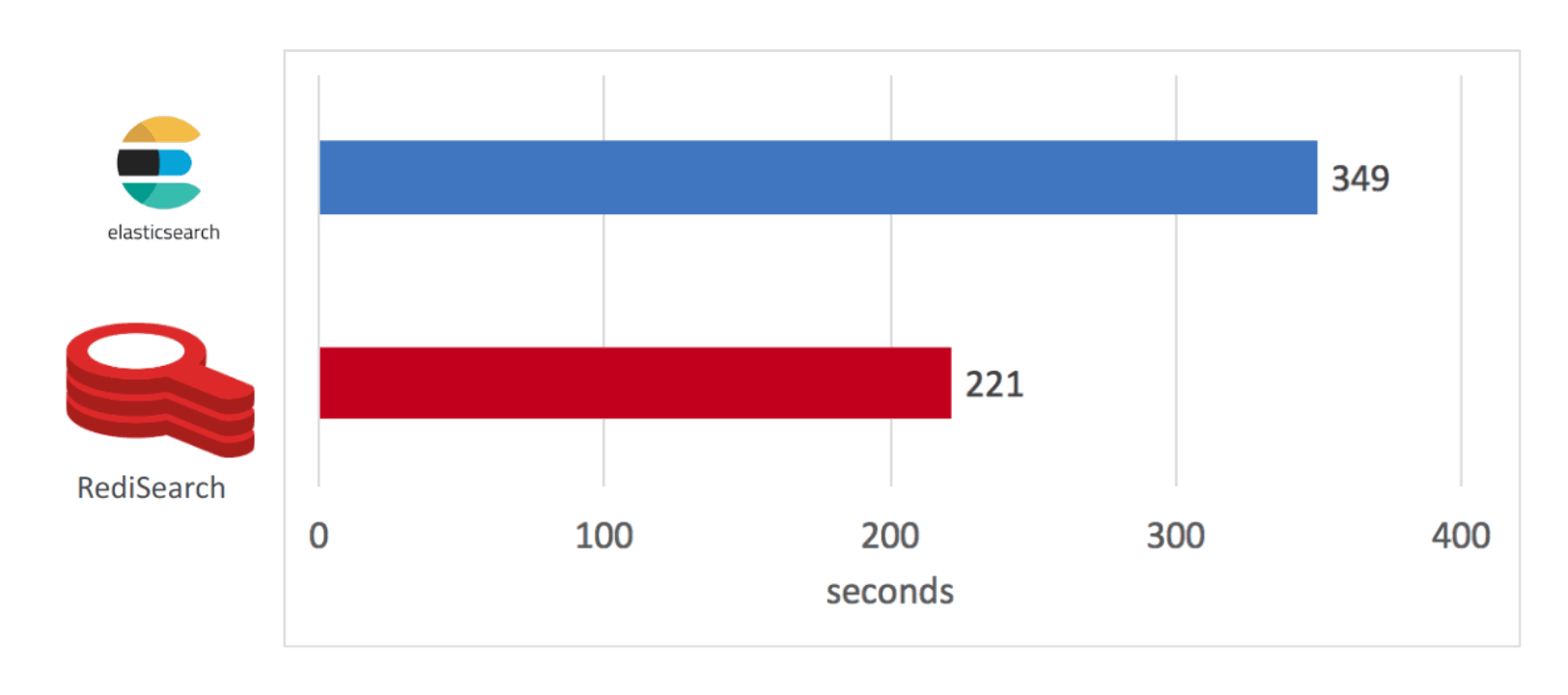
Querying Performance