This is a list of wordsRediSearch
DEMYSTIFIED
RediSearch Demystified
Search Engines
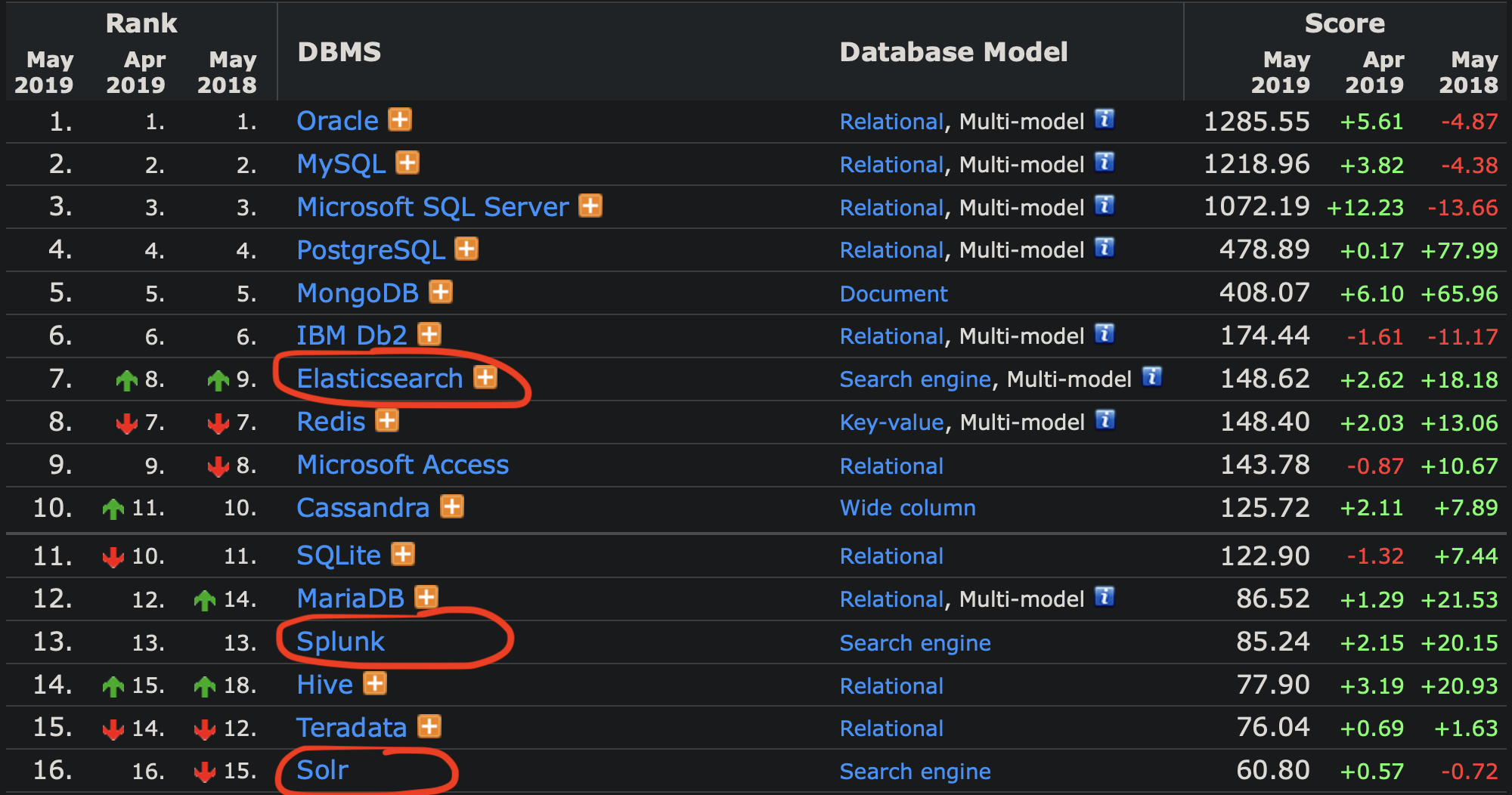
Search Engine
Indexing
Documents
Inverted Index
Tokenization
Stop words
Stop Words
Stemming
English Stemmer
Romance Stemmer
Synonyms
Tag Fields
Query Language
Query Language
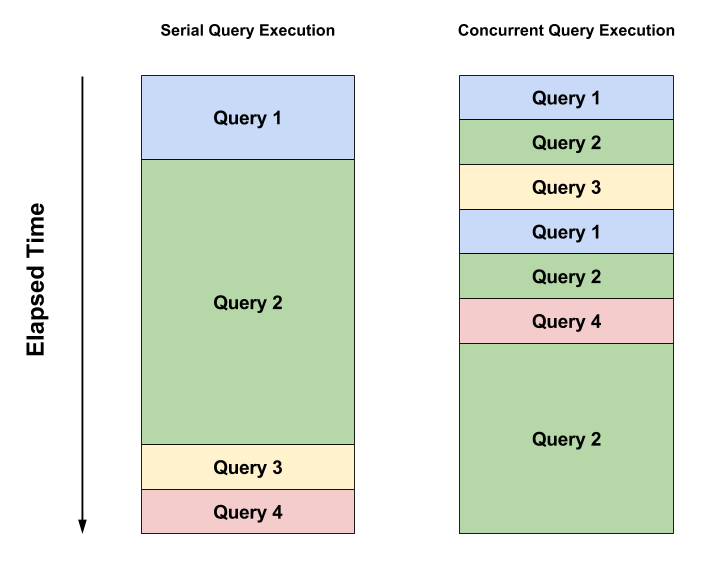
Query Execution
Fuzzy Matching
Covfefe?
Phonetic Matching

AIHEOPDERF
Double Metaphone
Double Metaphone
Index Partitioning
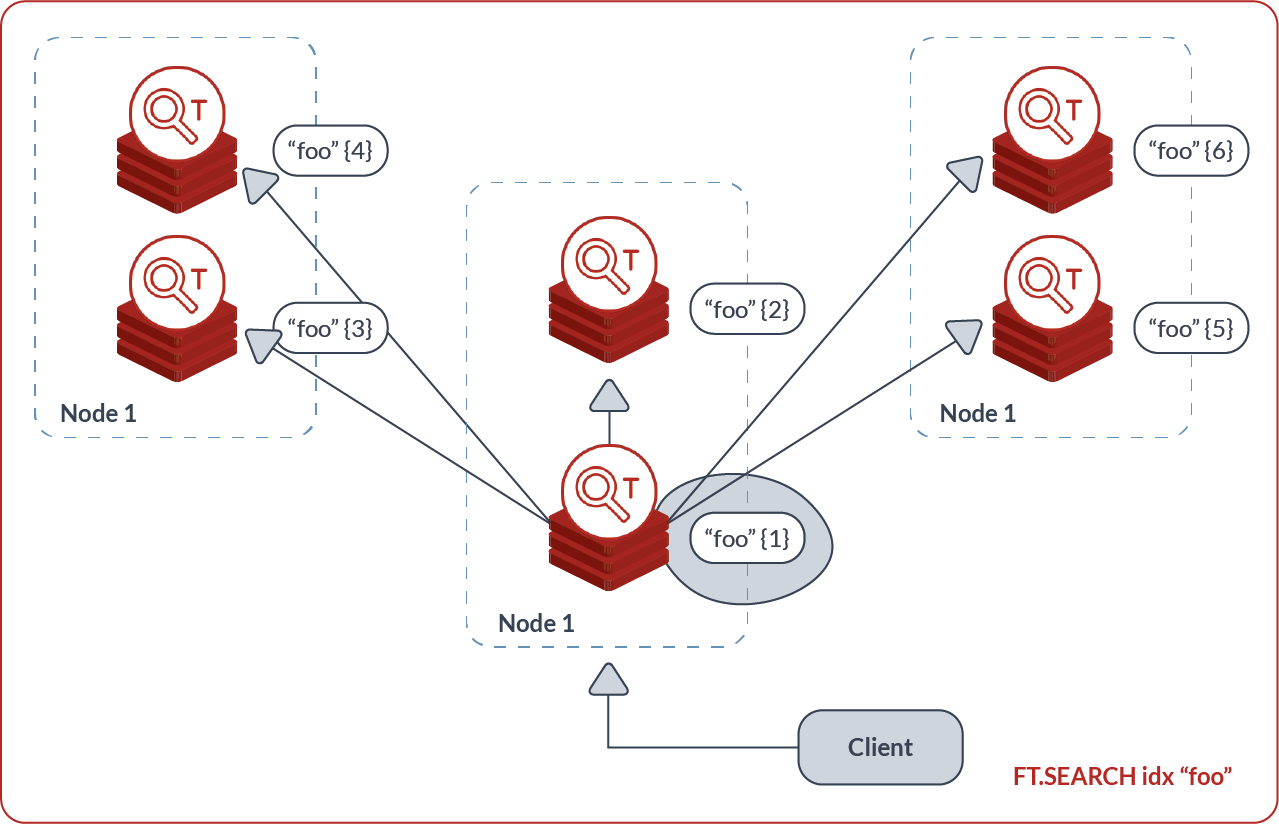
Concurrency